
From FEAR culture to TRUST culture
Often, after reading a tweet from Charity Majors, my obsession to NOT follow rules only because « we’ve always done it that way » inspire me to write a post. Hope you’ll enjoy it.
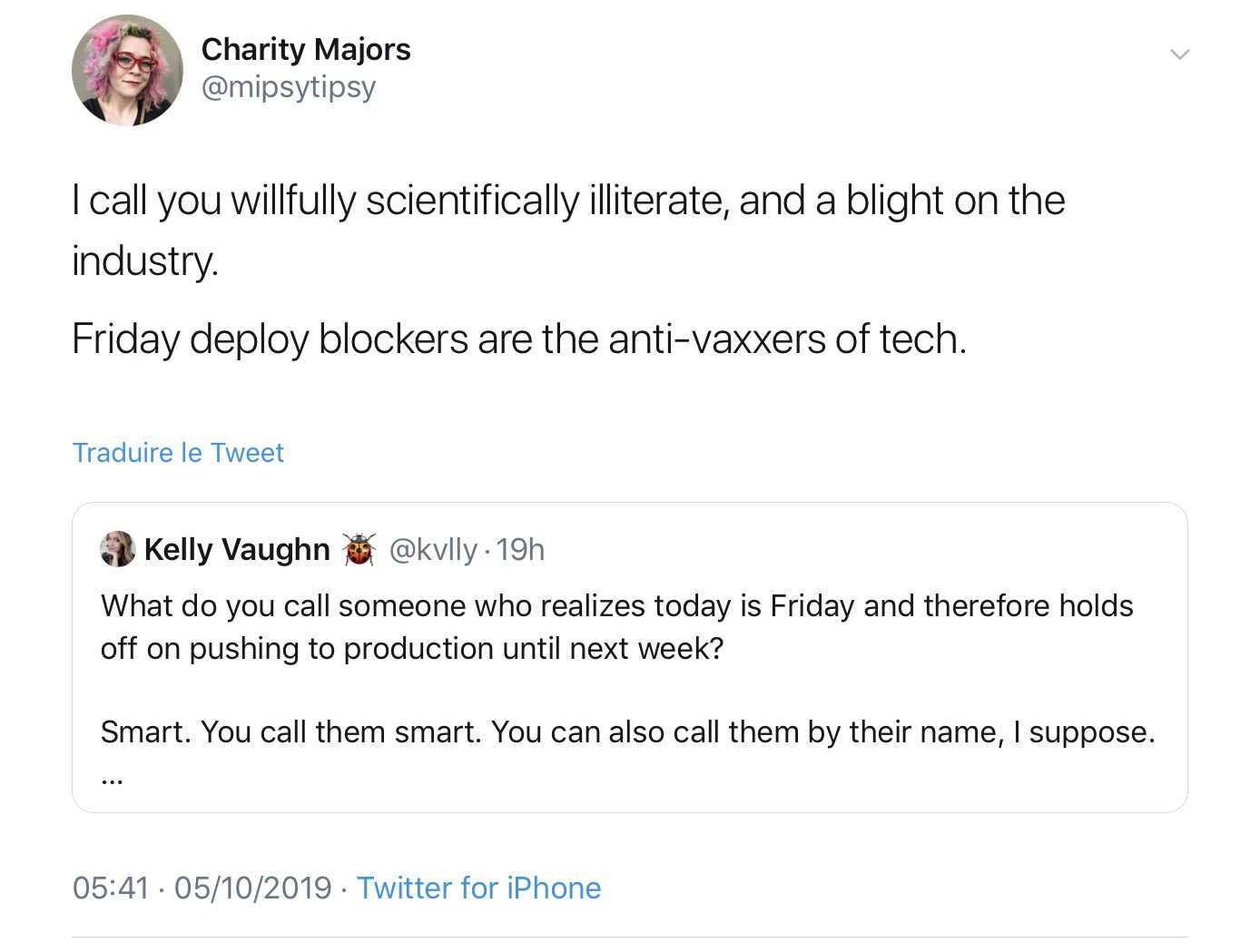
Forbid to push in production on Friday is a #DevOps anti pattern
More than just make Dev and Ops work better together, DevOps aims at delivering as soon as possible any developed and tested features to our users, get the expected value and having quick feedbacks.
Forbid to deploy on Friday is to lose 20% of time to deliver this value to your users. Sometimes, we even forbid it on Thursday afternoon or before Bank Holidays, thus forbid more than 30% of time !
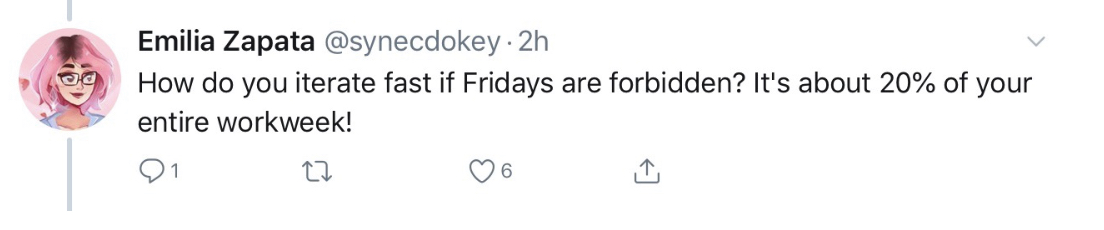
More than lose this important time, we give the impression that we are not confident of our CI/CD pipeline, of our tests, maybe not even trust our teams. If you are not confident to deploy on Friday, why are you to do it any other day?
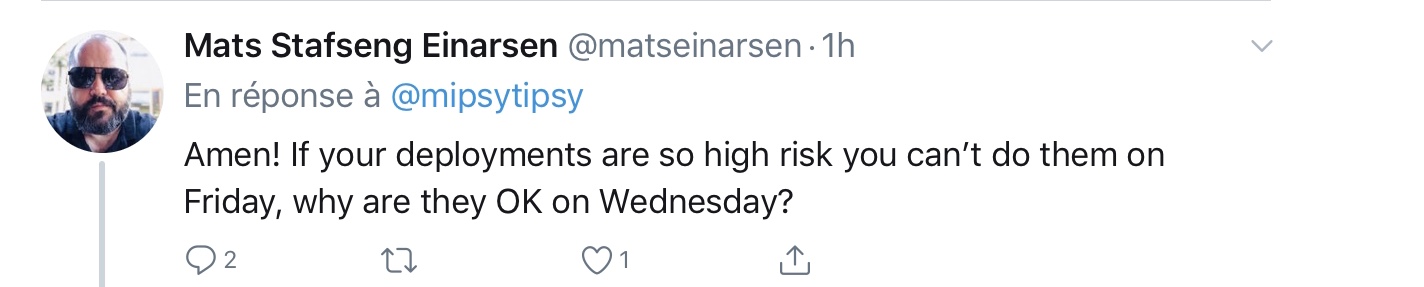
This rules implies than deploying is dangerous, risky. We should not FEAR to deploy in production.
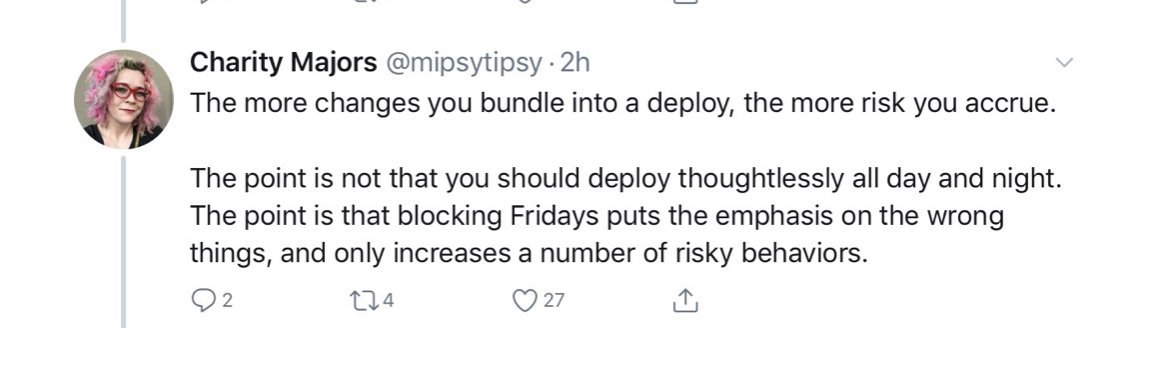
If you believe you are #DevOps, you should be able to deploy any times, nights and days, even on Friday!
Why do we have this rules?
Doom-mongers will tell you that this rules was not set only to please the boss. That you need it if you want to protect your week-end. It’s common sense, precautionary principle…

And to be fair, we all have many anecdotes and experiences of bad weekend. So even if you agree that we should break this rules, it can be hard to make the move.
Let’s step back a little bit. Why do we regret having deploy on Friday?
1- Deployment went wrong and you have to stay late, even overnight to fix it.
Having the right level of DevOps maturity, deploying should be event less. You can build this with a CI/CD pipeline, automated test who provide the right level of confidence, a blue-green deployment for a instant rollback, … You must concentrate on building trust on your build process. A lot of books might help you, my favorite is Continuous Delivery by Jez Humble.
2- Incident some time after the deployment, managed by “On Call team”
The real subject here is why the team did not detect the issue before or at least right after the deployment?
First of all, the team must monitor their application in production after the new release. It’s criminal to deploy on Friday at 5pm and then go have a beer.
Then, do the team have the right level of observability to detect the issue? During a DevOps transformation, you must not only improve deployment pipeline and testing but also improve the way you monitor your systems. With increasing complexity, classic monitoring and alerting are no more enough to detect abnormal behavior of our systems. About Observability, I highly recommend this white paper by Charity Majors and Liz Fong-Jones, as well as this ebook from D2SI and my friend Benjamin Gakic.
Finally, why the incident is managed by a separate “On Call team”? A responsible team should assume their own actions, risk taken and obviously the consequence. Thus, the team will make everything to not lose nights and weekend, by building a safe process for their release.
3- Unknown unknowns

Charity Majors Chaos Engineering and Observability
Last but not least, the unknowns. Deployment were seamless hundred times. But this time, something went wrong. A concurrent deployment do a change on the same file. A server with a different system date believe it’s already tomorrow… All these issues never happened before, and probably will never occur again.
They are part of the risks, even if it’s more frustrating on Friday’s nights. But do we not go outside because a meteorite might fall on us?
The best thing to do is to be prepared, and Chaos Engineering practice are a great way to do it.
To summarize, with the right level of DevOps maturity, this rules should not exist anymore.
How to move on?
You want to move on and allow your teams to deploy any times they can. But a small voice still say no (might be your boss or the Head of Operations). My proposition is to have a “licence to deploy”.

Principle is quite simple. If a team has the right level of maturity:
- Great coverage of automated tests,
- CI/CD pipeline
- Feature flipping to activate/deactivate new features
- Instant rollback capability, like blue-green deployment
- Is On Call
- …
This proposition should be review adapt to your context and needs.
In summary, instead of having a rules to forbid to deploy on Friday by default, let’s trust your team by default and deliver them a licence to deploy anytime.
You may also add some point than make you lose your licence until you did a new training or fix some technical debt:
- Forget to adapt monitoring system during deployment and sending false alarm: -1pt
- 3 consecutive deployment with rollback: -3pts
- Launch a deployment and go for lunch or having a beer without checking the results: – 6pts
- …
Deployment distribution graph is an interesting way of measuring your level of DevOps maturity
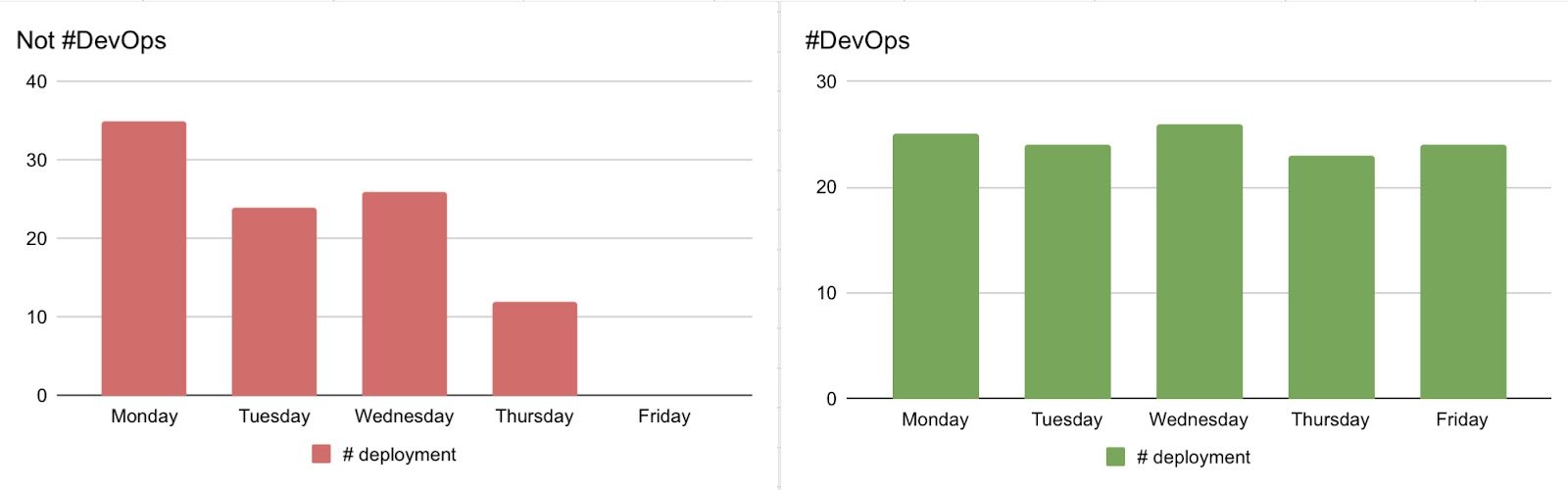
However, it’s still a number, if your whole strategy of change is based on it, teams might just wait for Friday for their deployment to please you. My favorite KPI is the level of code stock, that’s to say the code done (and tested) that is not in front of its public.
Thus, removing the rules forbidding any deployment on Friday, eventually with a licence to deploy, we move from a culture of FEAR/PROHIBITION to a culture of TRUST.

As a bonus, we all face the issue of recruiting Tech profiles, being able to tell that you trust your teams enough that deploying a Friday is part of your company culture might help attracting talents !