
Afin d’améliorer son TTM (Time to Market) pour répondre aux exigences de vitesse et de qualité indispensables à toutes équipes digitales dans un monde de plus en plus complexe et exigeant, la plupart des entreprises ou département IT se sont dans une transformation Agile puis DevOps . Au fil des ans, l’aspect technique – les outils, l’industrialisation – est apparu comme la partie la plus simple de la transformation, car au-delà du débat d’expert, la profusion des outils permet de répondre assez facilement à l’ensemble des besoins qui émergent. La partie la plus complexe a été d’amorcer le changement culturel nécessaire à la mise en place d’un système industriel de production au service d’équipes, elles-mêmes au service de la valeur produite pour leur client.
Ce système s’appuie sur les six éléments du diagramme ci-dessus.
Feature Team
Le fonctionnement historique en cycle V avait apporté un découpage organisationnelle lié à la méthode de développement d’un produit logiciel. A chaque étape du cycle, une équipe passait le relais à une autre, déléguant ainsi sa responsabilité. La dernière étape de la chaîne mettait ainsi uniquement les exploitants face aux clients finaux. Le cycle était long, en moyenne 18 mois de l’idée à sa mise en production, et n’était plus adapté aux projets digitaux qui demandent une réactivité quasi immédiate à l’ensemble des maillons de la chaîne.
La solution utilisée par les géants de l’internet est basée sur un principe simple, exprimé par Werner Vogels, CTO d’Amazon : « We have this principal of “you build it, you run it”. You are responsible for what the customer sees, in short. »
Dès lors, une seule équipe fabrique le logiciel et l’exploite dans la durée. L’ensemble des compétences est réuni au sein de l’équipe : UX, UI, développement, analyse fonctionnelle, test, exploitations, architecture… L’équipe s’assure du recouvrement des compétences, y compris en cas d’absence d’une personne, par le « 0 truck factor » – c’est-à-dire, même si elle passe sous un camion (test non effectué en grandeur nature).
Agilité d’entreprise
Le fonctionnement par Feature Team apporte la responsabilité et l’autonomie nécessaire pour produire de la valeur pour les clients de l’entreprise. Mais les équipes évoluent dans un cadre d’entreprise qui doit pouvoir également s’adapter plus facilement aux changements.
Pour aligner les équipes, on peut se baser sur le concept des OKR (Objective-Key-Result) de Google (et inventé chez Intel) : les objectifs sont ambitieux, les principaux résultats sont facilement mesurables, ils sont publics et connus de tous dans l’entreprise et ne sont pas synonyme d’évaluation des employés. Chaque équipe peut alors choisir comment elle va y contribuer et il faut inspecter régulièrement pour suivre l’évolution et l’amélioration apportée pour l’entreprise.
S’aligner sur des ambitions n’est pas suffisant, il faut accompagner l’ensemble des équipes supports, telles que les ressources humaines ou le contrôle de gestion pour permettre aux équipes d’être les plus efficaces et autonomes. Une équipe de PMO peut par exemple adapter les besoins de ces services aux contraintes d’un fonctionnement Agile en mettant en place, par exemple, des budgets en mode capacitaire et une académie pour former nos nouveaux arrivants à l’ ADN DevOps & Agile et les pratiques d’entreprise.
Chaîne industrialisée
Même si, comme évoqué en début de cet article, ce n’est pas le sujet le plus complexe, cette chaîne industrialisée est essentielle pour outiller le cycle de vie des logiciels conçus et exploités par les équipes.
La transformation DevOps de l’entreprise nécessite d’adresser de multiples domaines d’activité :
- gestion des artefacts Agile (backlog, user stories…),
- gestion de la configuration,
- gestion des codes sources,
- gestion des données de test et de production,
- tests,
- déploiements d’applications,
- gestion des environnements,
- surveillance de l’activité des infrastructures et des applications.

Si vous cherchez un outil pour une de ces étapes, nous vous recommandons la Table Périodique DevOps de XebiaLabs.
Management – Servant Leader
Pour accompagner les équipes, il est nécessaire de revoir également les pratiques en terme de management, pour passer d’un manager à un leader au service de ses équipes :
- A l’écoute de ses collaborateurs, pour mieux comprendre leur besoins et attentes,
- Doté d’une grande empathie pour aider à comprendre même ce qui n’était pas dit et qui pouvait poser problème à l’équipe,
- Capable d’aider et d’assister les autres pour leur donner la possibilité de passer les difficultés,
- Etre en conscience de ce qui se passe pour lui et pour les autres,
- Utiliser son esprit critique et son expérience pour challenger les propositions de ses collaborateurs et leur permettre de se poser les bonnes questions,
- Adepte de la conceptualisation, pour permettre la prise de recul et permettre de penser au-delà des réalités au jour le jour,
- Capable de prévoyance pour permettre de prendre en compte les leçons du passé et en tirer des conclusions pour l’avenir,
- Etre un bon intendant, pour permettre la réalisation effective des attentes de ses collaborateurs,
- Engagé dans l’évolution des personnes, pour que chaque personne puisse grandir et se développer au sein du collectif.
En résumé, il faut cultiver le « lâcher prise », prendre conscience qu’on ne peut pas tout contrôler et développer un management par l’influence et le réseau plutôt que par la hiérarchie et le contrôle, plus efficace pour favoriser l’innovation, la vitesse et l’engagement des équipes.
Excellence Opérationnelle
L’Excellence Opérationnelle est centrée sur les besoins du client, l’optimisation des processus et surtout la capacité des équipes à trouver elles-mêmes des solutions. Ce dernier point est clé. Pour reprendre Toyota : « Tout problème doit être vu comme une occasion d’apprendre, car l’entreprise elle-même devient une organisation apprenante ».
Dans un cycle de production Agile et DevOps organisé autour de Feature Teams, les équipes délivrent de plus en plus vite. Le SI est de plus en plus sollicité. L’enjeu est donc de le stabiliser pour maintenir la performance. Quand ont fait 3 à 4 MEP chaque année, le temps était pris pour tout vérifier, tout tester, tout réparer le cas échéant.
Aujourd’hui, avec plusieurs releases par semaine, il est impossible de tout sécuriser avec des process humains et de pur contrôle.
On propose donc deux stratégies pour accompagner cette transformation :
- Passer de la QoS (Qualité de service) à la QoE (Qualité d’Expérience Utilisateur),
- Passer de l’Exploitabilité (respect des normes d’exploitations) à la Sûreté de Fonctionnement (aptitude à délivrer un service avec une confiance justifiée et à éviter des défaillances du service plus fréquentes ou plus graves qu’acceptables).
Ce changement de perspective conduit, entre autres, à mettre en place pour la QoE des chantiers d’amélioration sur la durée de traitement des irritants clients, de la vitesse et de la performance des sites web, et la gestion des incidents majeurs et de crise, ainsi que les retours d’expérience.
Pour mieux intégrer les partenaires à la démarche, on peut réfléchir à la mise en place de XLA, pour eXperience Level Agreement, des SLA (Service Level Agreement) 2.0 alignés avec la volonté de mettre le client au cœur de nos exigences de qualité.
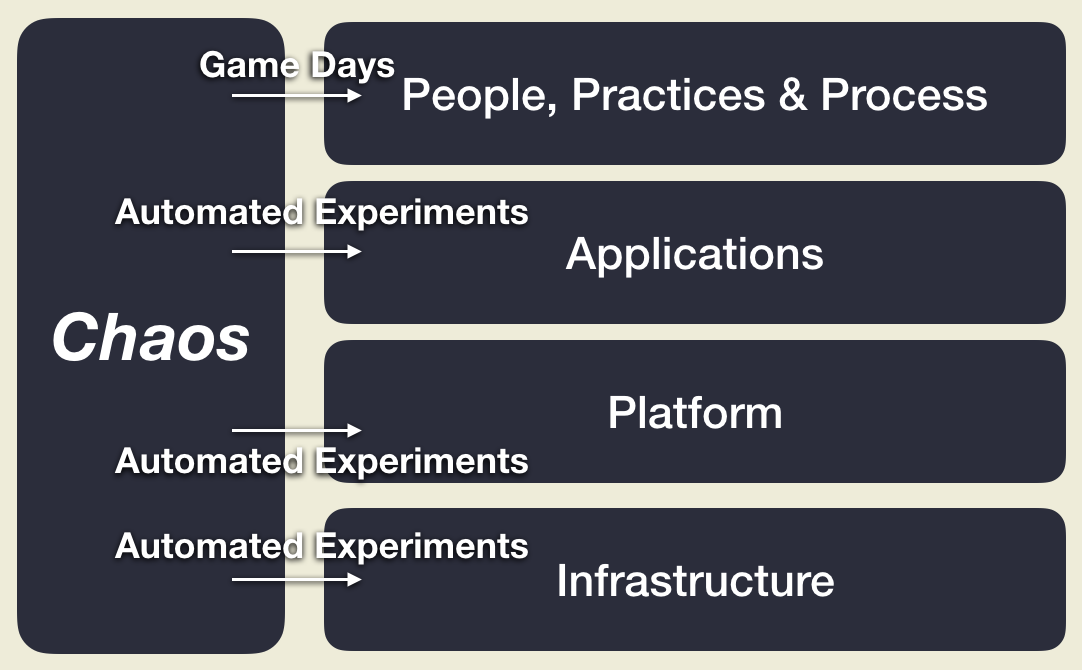
Chaos Engineering
L’ingénierie du chaos, ou Chaos Engineering, est une discipline émergente qui vise à éprouver la solidité de l’infrastructure socio-technique afin de toujours mieux préserver la qualité de service. Cette pratique expérimente les lacunes et les faiblesses des applications et de l’infrastructure sur un système distribué. La complexification et l’automatisation des systèmes rendent cette pratique de plus en plus importante pour maintenir l’expérience utilisateur. Expérimentée depuis 7 ans par des pure-player comme Netflix, elle s’est structurée autour de process et d’outils dédiés.
La question que pose cette discipline est : A quel point votre système est-il proche du précipice et peut sombrer dans le chaos ?
« Everything fails all the time. »
Werner Vogels, CTO Amazon
A chaque instant, quelque chose, quelque part, tombe en panne. Il ne s’agit plus de croiser les doigts pour que ça n’arrive pas, mais de mettre en place la résilience nécessaire dans nos systèmes pour tolérer les pannes, et de s’assurer que cette résilience est opérationnelle et fiable en production.
Il s’agit alors d’effectuer des tests en production :
- Expérimenter pour éprouver nos systèmes : plutôt qu’attendre une panne, il s’agit d’en introduire une pour tester la résilience du système,
- Expérimenter pour apprendre : il ne s’agit pas de provoquer le chaos pour s’amuser, mais bien pour découvrir des faiblesses inconnues de nos systèmes.
Pour en savoir plus : Qu’est-ce que le Chaos Engineering ?
En synthèse

Le chemin vers un système industriel n’est pas une ligne droite, c’est avant tout une aventure humaine pleine d’expérimentations, de succès et d’échecs qui permet à tous de sortir grandis et d’accepter que ce soit une aventure sans fin, que la transformation comme l’amélioration soit continue.
Pour en savoir plus : « Mettre en œuvre DevOps – Comment évoluer vers une DSI agile – 2nd Edition »
