
Discipline de l’expérimentation sur un système distribué afin de renforcer la confiance dans la capacité du système à résister à des conditions turbulentes en production.
La discipline d’ingénierie du chaos a été initiée par Netflix et le principe a été défini sur http://principlesofchaos.org/ dans la foulée des Chaos Monkey et de la Simian Army.
Malgré la multitude de conférences à travers le monde, le terme n’a cependant pas encore percé autant :

Pas encore.
De nombreux signes indiquent que cette discipline va exploser dans les prochains mois.
Le concept est entré dans le Technology Radar de ThoughtWorks :

De nombreuses communautés de pratiques éclosent à travers le monde :
- Paris Chaos Engineering Community
- London Chaos Engineering Community
- Chaos Engineering Hamburg
- New York Chaos Engineering Community
- Chicago Chaos Engineering Community
- Twin Cities Chaos Engineering Community
- Vancouver Chaos Engineering Community
- Seattle Chaos Engineering Community
- Salt Lake City Chaos Engineering Community
- Silicon Valley Chaos Engineering Community
- Korea Chaos Engineering Community
- Shanghai Chaos Engineering Community
- Melbourne Chaos Engineering Community
ainsi que le Chaos Community google group.

Au niveau de la France, on voit émerger progressivement le concept dans quelques articles :
- Netflix engage des “ingénieurs du chaos” pour mettre à l’épreuve son service — ZDNet — Septembre 2014
- Principes d’Ingénierie du Chaos de Netflix — InfoQ — Septembre 2015
- AWS Summit Gameday : Testez la résilience de vos applications — Blog D2SI — Juin 2017
- Chaos Engineering ou le stress ultime des applications et de l’infrastructure — Le Mag IT — Novembre 2017
- Voyages-sncf mise sur l’ingénierie du chaos pour éprouver son infra — Journal du Net — Novembre 2017
- Voyages-SNCF sème, volontairement, le chaos dans sa production informatique — ConvergenceIT — Novembre 2017
- Meet up sur le Chaos engineering — OUI Talk — Novembre 2017
La discipline se répand dans de nombreuses sociétés et de plus en plus de personnes y contribuent à travers le monde :
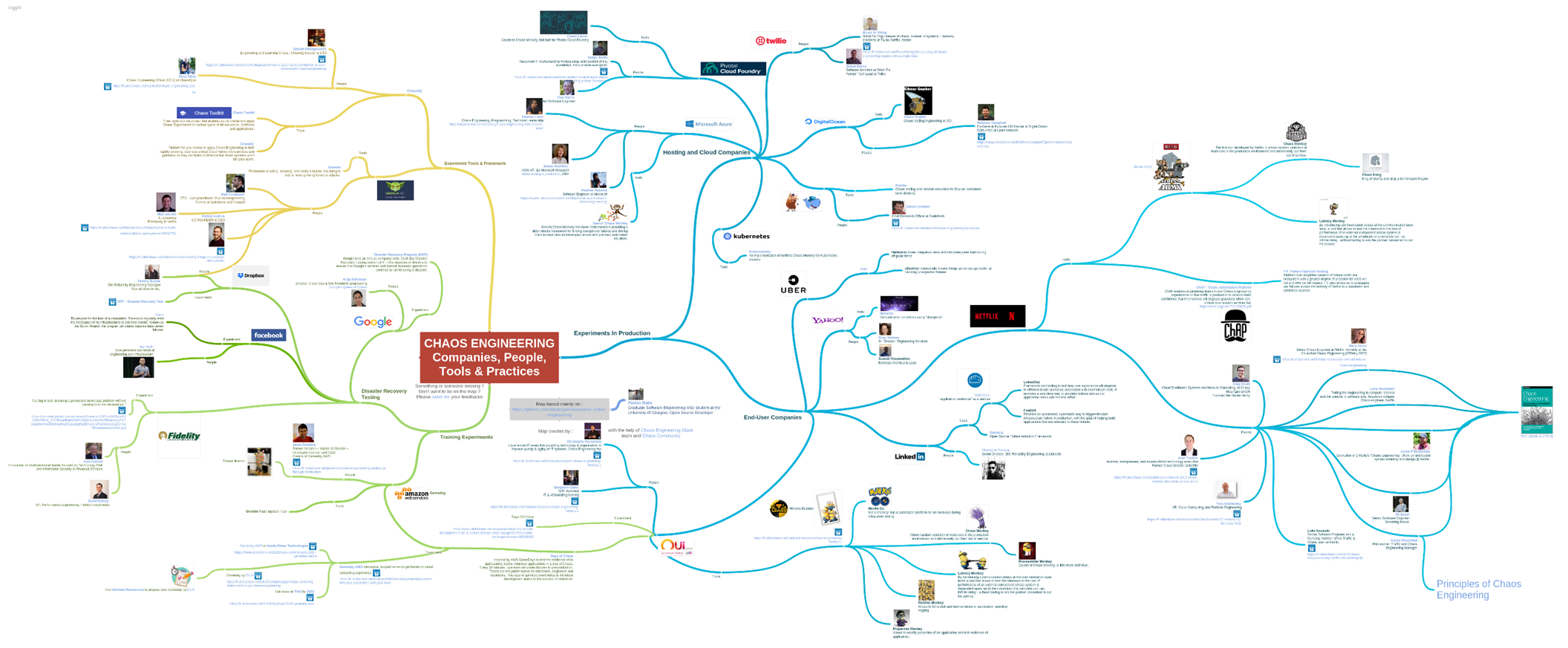
Des expériences en production — de type Chaos Monkey— existent dans des sociétés d’hébergement et cloud (Azure, Digital Ocean, Pivotal Cloud Foundry, Twillio, …) comme des sociétés qui s’adressent à des clients finaux (Netflix, LinkedIn, Uber, OUI.sncf, …).
De plus en plus de Gameday sont effectués lors de conférences comme en entreprise, Amazon bien sur, mais également Veolia Water Technologies ou DiUS, qui a d’ailleurs compilé une synthèse de ce qui est nécessaire pour en réaliser un.
OUI.sncf a décliné le concept GameDay en créant les Days-of-chaos à destination de toutes les équipes IT et visant à l’entrainement à la détection, au diagnostic et à la résolution des incidents de production. Les Feature Teams jouent sur leur véritable environnement de preproduction, sur leur application et non sur une application “bidon” Unicorns.Rentals sur Amazon AWS.
La mise en place de Test de Récupération après Sinistre (Disaster Recovery Testing) a toujours existé, mais doit passer de la pratique exceptionnelle à la pratique en continue, comme le programme DiRT chez Google, Storm chez Facebook, DRT chez Dropbox et même dans le secteur bancaire, comme à Fidelity Investments.
Qui sera le prochain ?
Peut-être vous !
Pour cela, vous pourrez vous aider de solution comme ChaosToolkit de ChaosIQ ou la plateforme de Gremlins Inc.
En espérant que vous nous rejoignez bientôt dans ces expérimentations en ingénierie du Chaos .
Pour échanger, rejoignez-nous sur le groupe Meetup Paris Chaos Engineering Community http://meetu.ps/c/3BMlX/xNjMx/f